I monitored 6 LLM APIs for 7 days. Here's what I found.
60,000 probes across GPT-4o-mini, Claude 3.5 Haiku, Gemini 2.0 Flash, Llama 3.3 70B, DeepSeek Chat, and Mistral Small. Real latency numbers from continuous monitoring.
Why
If you’re building on LLM APIs, the provider docs show best-case latency numbers. Your users experience the p95.
I built llmprobe, an open-source Go CLI that probes LLM endpoints and measures time to first token (TTFT), total latency, and generation throughput. No SDKs, just raw HTTP and SSE parsing.
I pointed it at 6 models through OpenRouter and let it run for a week.
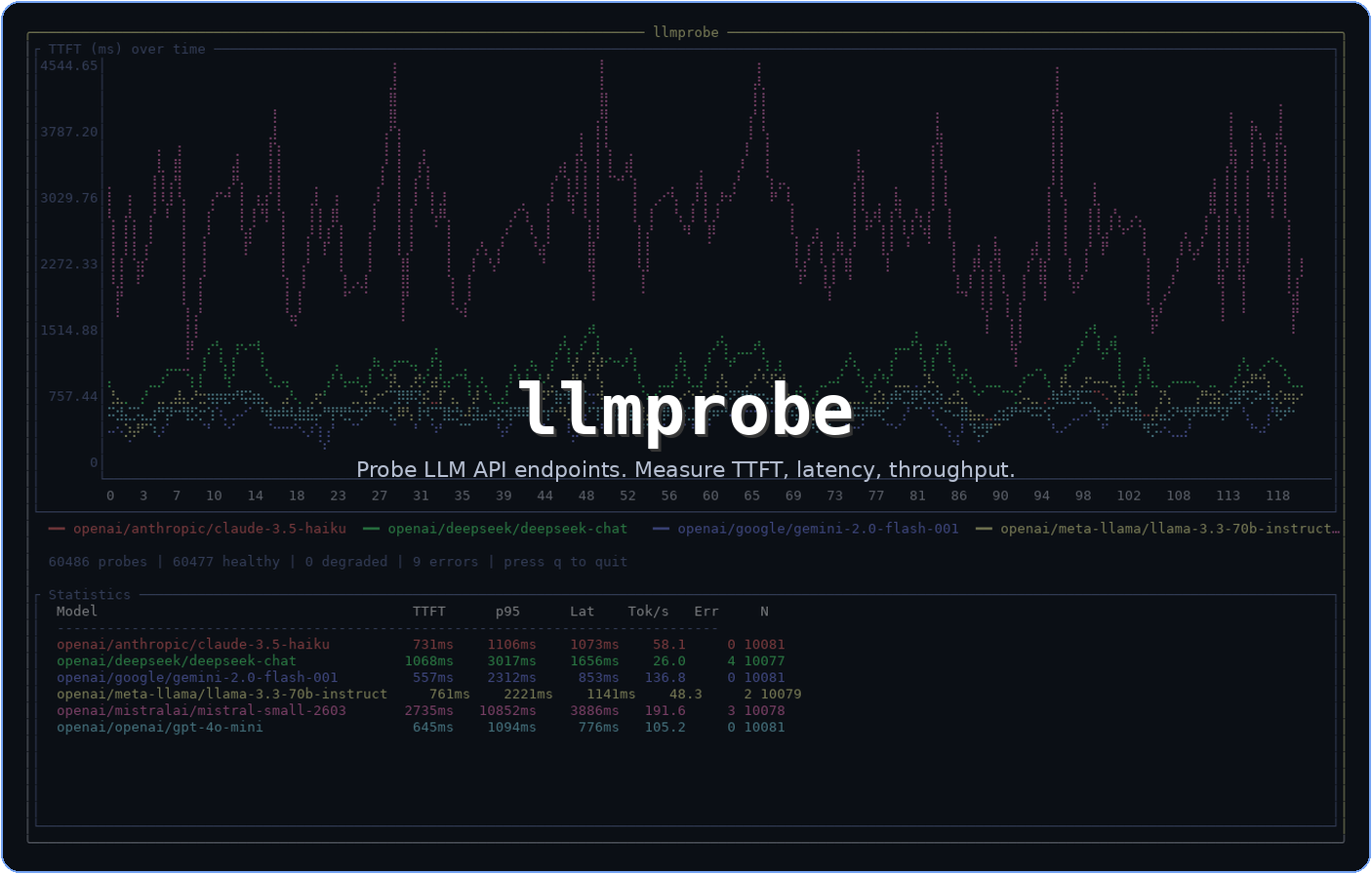
Setup
Every 60 seconds, llmprobe sent a minimal probe (“Hello”, max 20 tokens) to each model. The prompt is intentionally tiny to isolate infrastructure latency from model reasoning time.
Models: GPT-4o-mini, Claude 3.5 Haiku, Gemini 2.0 Flash, Llama 3.3 70B, DeepSeek Chat, Mistral Small.
Total probes: 60,480 (~10,080 per model).
The numbers
| Model | TTFT p50 | TTFT p95 | Latency | Tok/s | Errors |
|---|---|---|---|---|---|
| GPT-4o-mini | 645ms | 1,094ms | 776ms | 105.3 | 0 |
| Claude 3.5 Haiku | 731ms | 1,106ms | 1,073ms | 58.1 | 0 |
| Gemini 2.0 Flash | 556ms | 2,313ms | 853ms | 136.8 | 0 |
| Llama 3.3 70B | 761ms | 2,221ms | 1,141ms | 48.3 | 2 |
| DeepSeek Chat | 1,068ms | 3,017ms | 1,656ms | 26.0 | 4 |
| Mistral Small | 2,735ms | 10,852ms | 3,886ms | 191.6 | 3 |
p50 vs p95 tells different stories
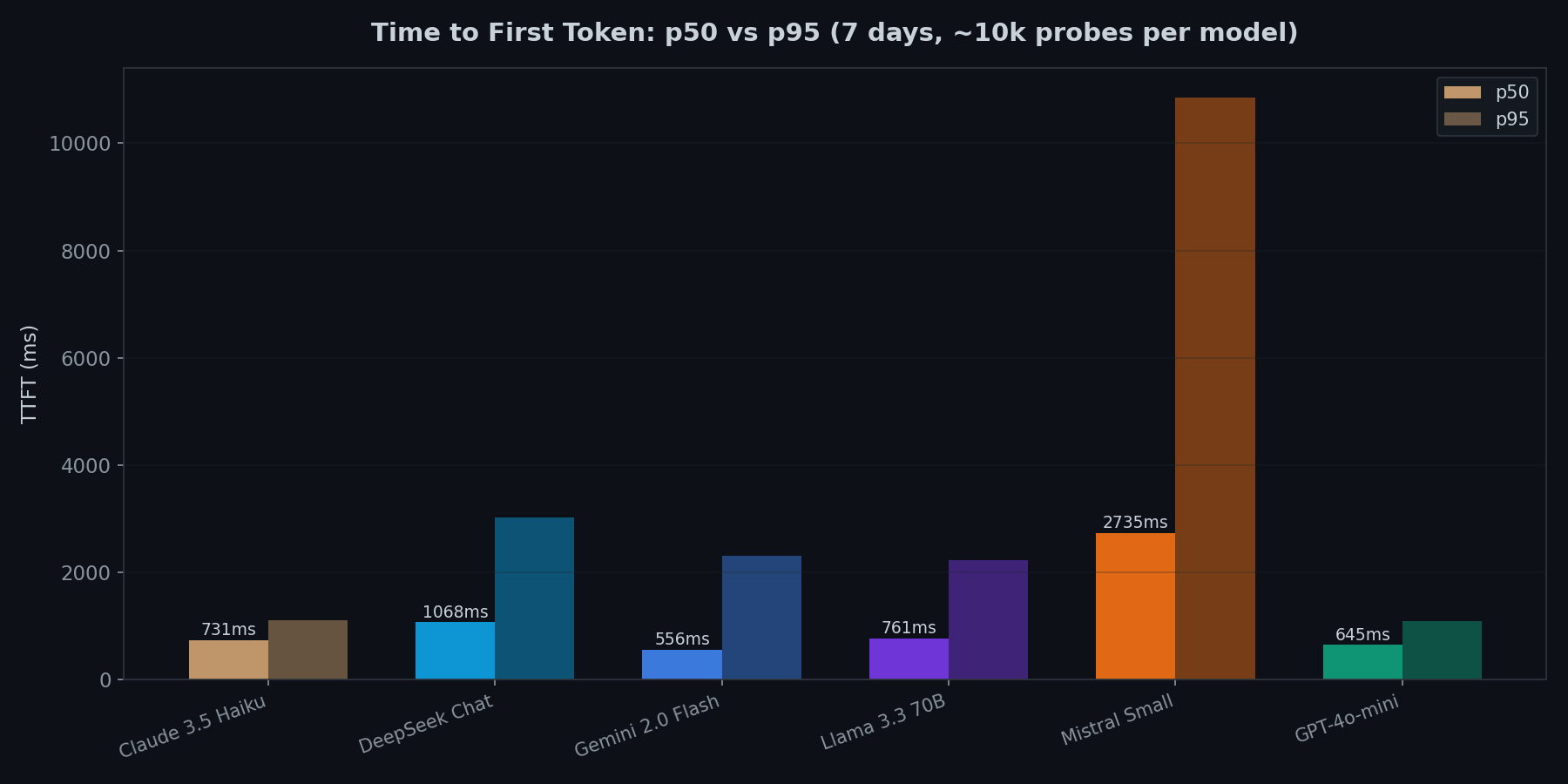
Gemini 2.0 Flash has the lowest median TTFT (556ms), but its p95 jumps to 2,313ms. That is a 4x multiplier. GPT-4o-mini and Claude 3.5 Haiku are more predictable: their p95 is only about 1.7x their median.
Mistral Small is the outlier. p50 of 2,735ms, p95 of 10,852ms. Roughly 5% of requests take over 10 seconds to start streaming. This was consistent across the full 7 days, not a temporary degradation.
Fastest first token != fastest generation
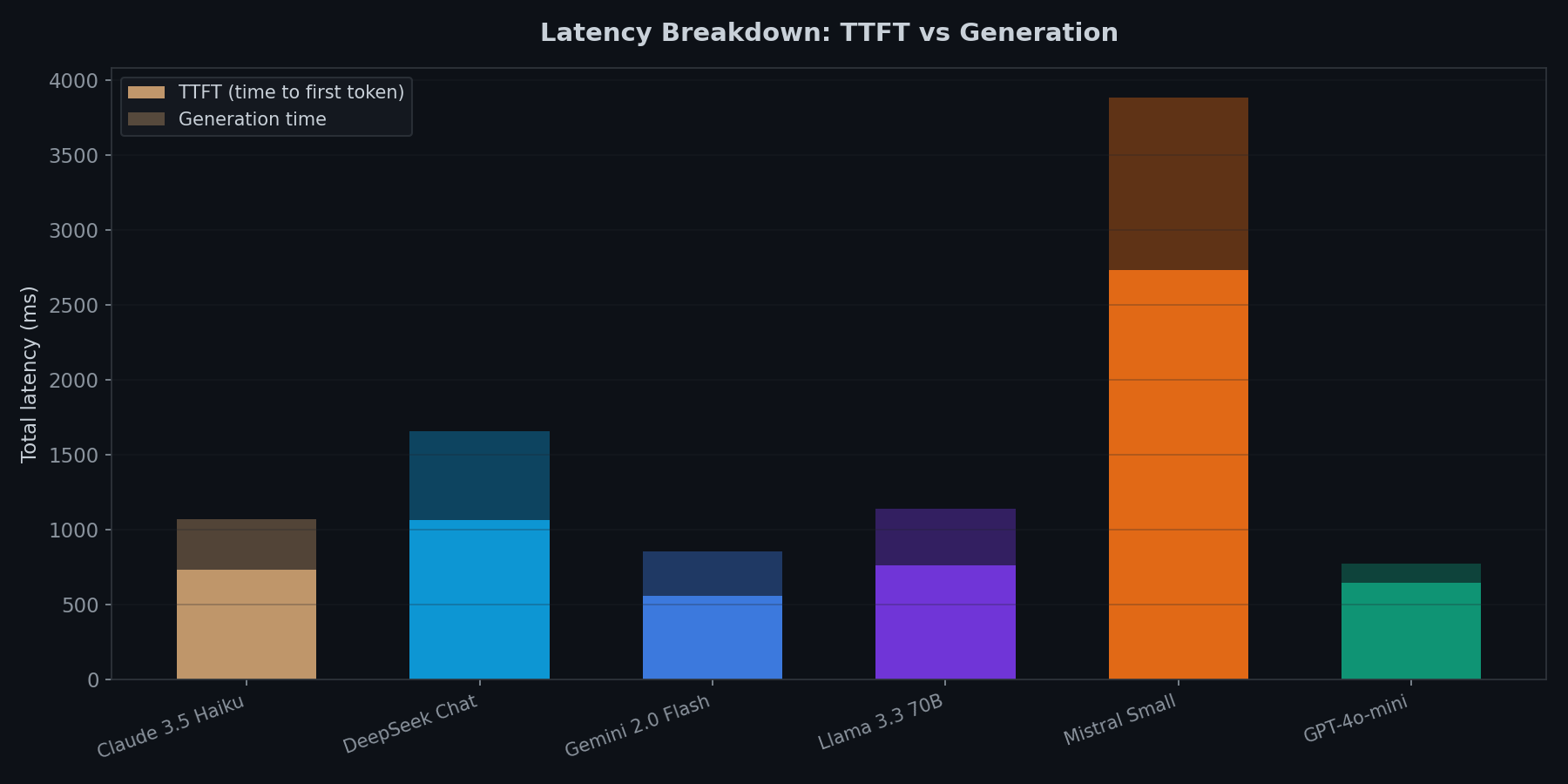
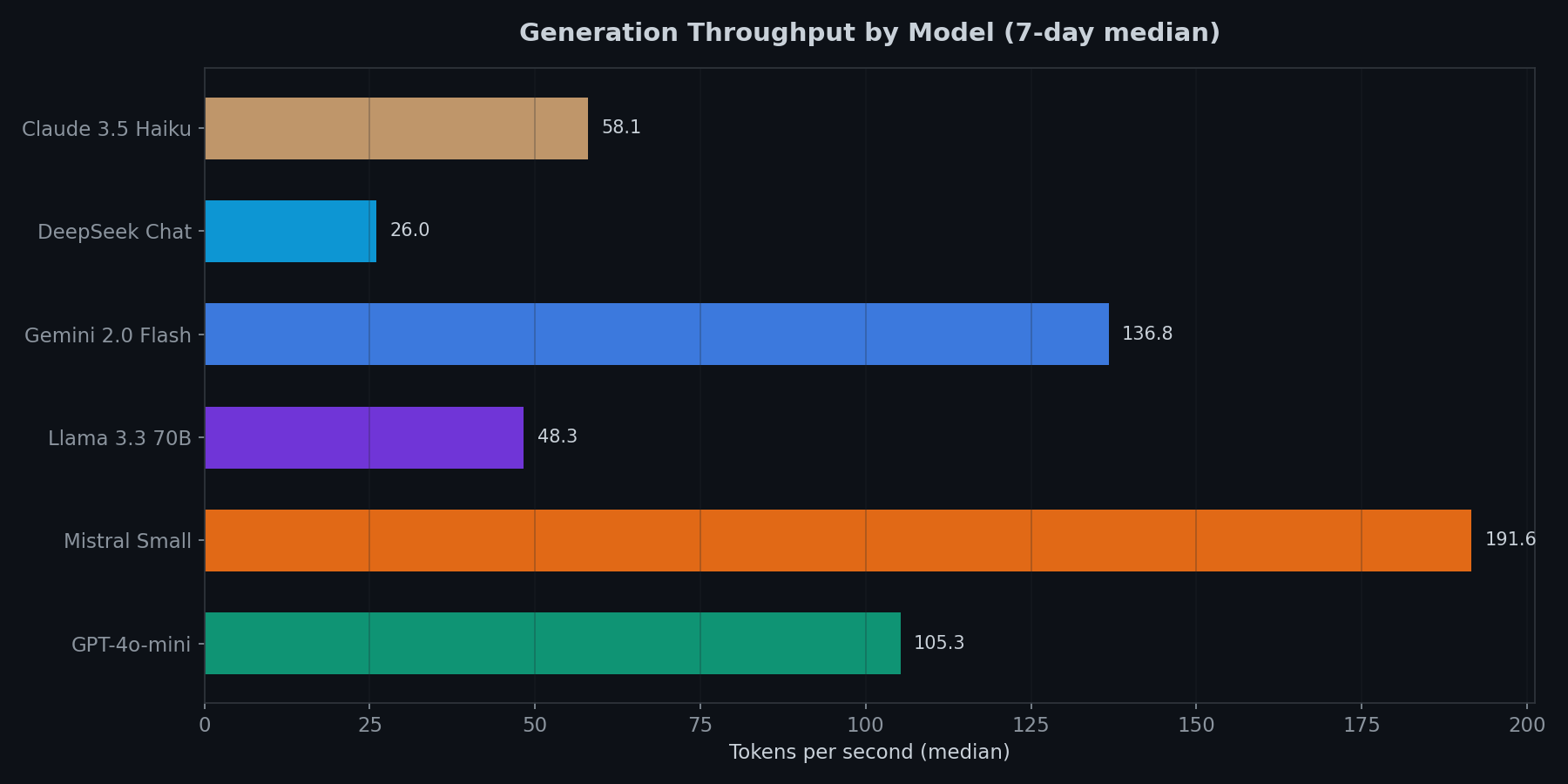
Mistral Small has the worst TTFT by far, but once it starts generating, it produces tokens at 191.6 tok/s (the fastest tested). Gemini 2.0 Flash is second at 136.8 tok/s.
DeepSeek Chat is slow on both fronts: 1,068ms TTFT and only 26.0 tok/s. The spread between fastest and slowest throughput is almost 8x.
Tail latency is where reliability breaks
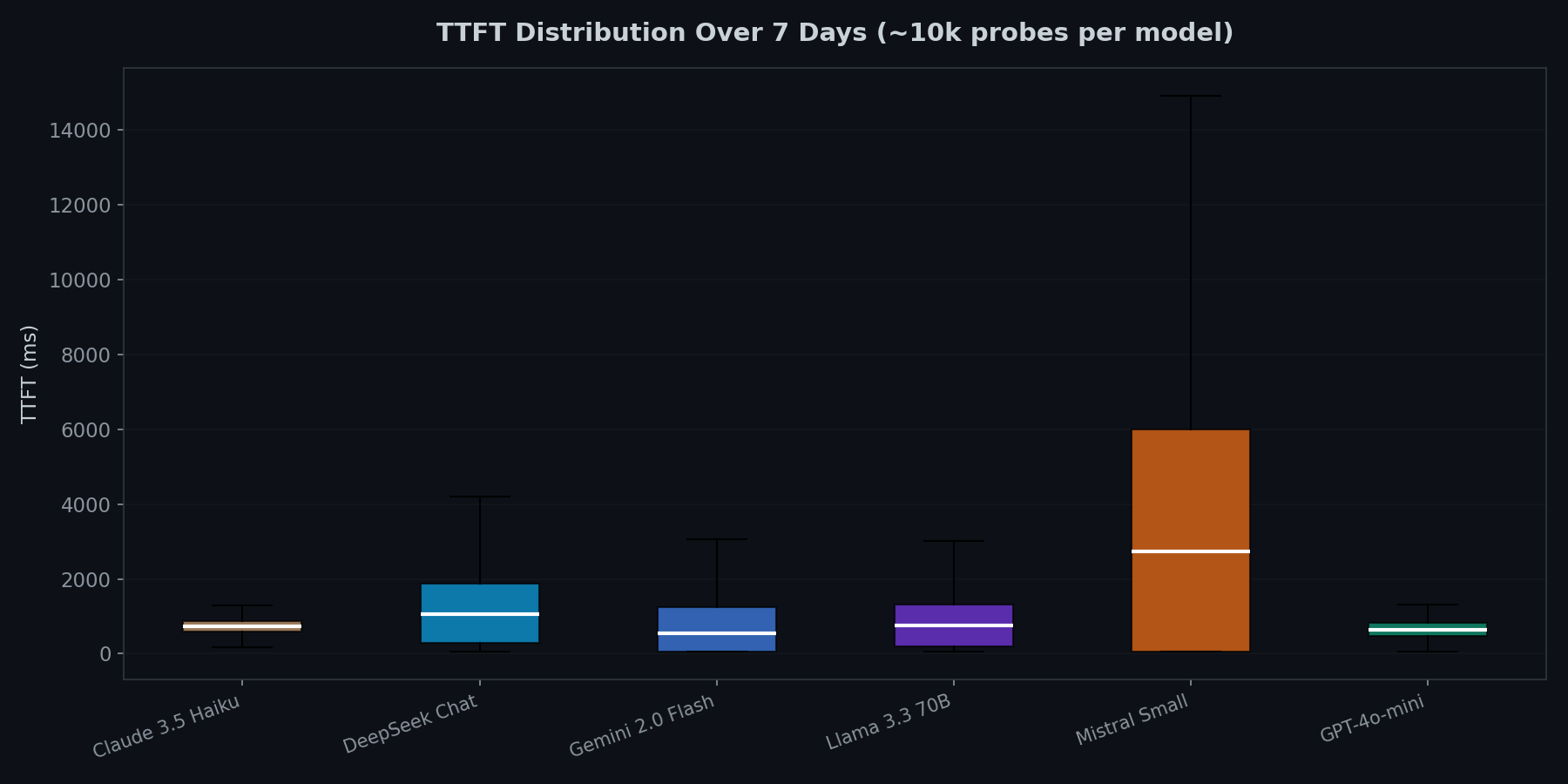
GPT-4o-mini and Claude 3.5 Haiku have the tightest distributions. You can set aggressive timeouts (2s) and rarely hit them. Gemini and Llama have longer tails. Mistral’s distribution is so wide it is effectively unpredictable for latency-sensitive work.
The 7-day view reveals patterns
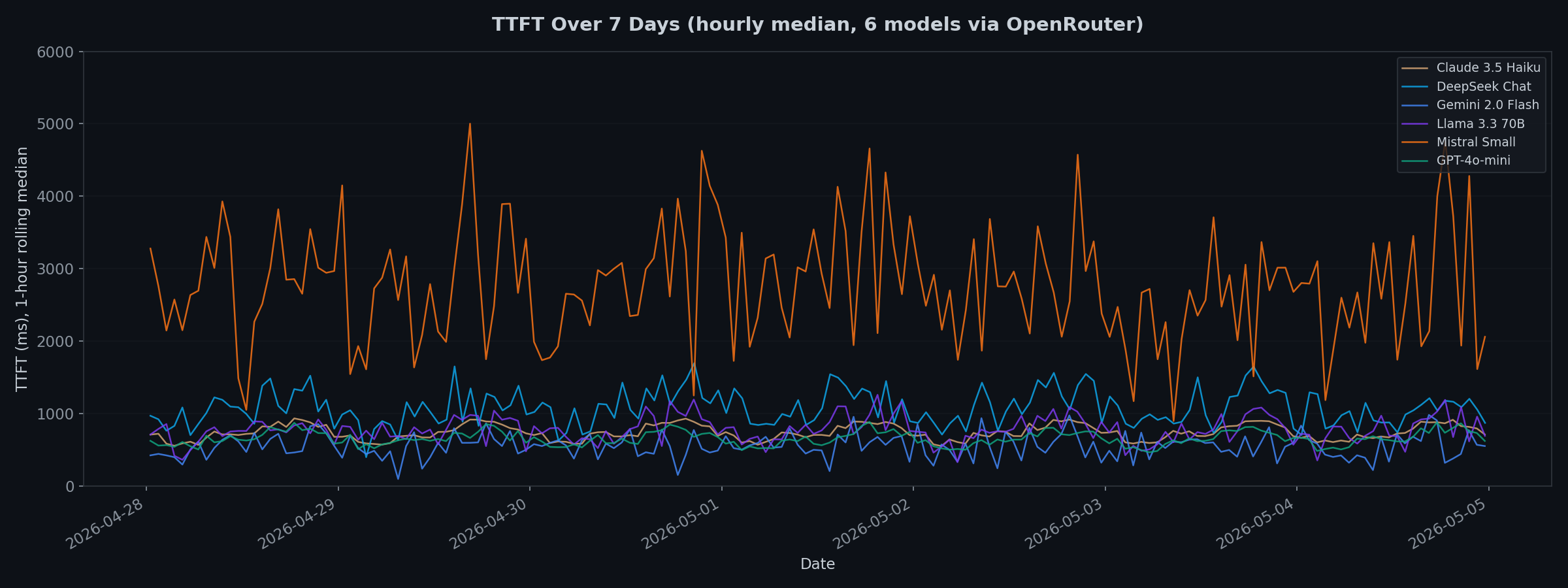
Running for 7 days exposes what quick benchmarks miss:
- Mistral Small had periodic latency spikes throughout the week, often exceeding 5,000ms.
- DeepSeek Chat showed elevated latency during certain windows, likely correlated with peak usage in Asian time zones.
- GPT-4o-mini and Claude 3.5 Haiku were remarkably stable. Their lines barely fluctuate across the full week.
Recommendations
Latency-sensitive (chatbots, real-time): GPT-4o-mini or Gemini 2.0 Flash. GPT-4o-mini is more predictable; Gemini is faster at the median but has wider tails.
Throughput-sensitive (batch, summarization): Mistral Small if you can tolerate the TTFT. Otherwise Gemini 2.0 Flash for the best all-around throughput without the latency penalty.
Reliability (SLA-bound): GPT-4o-mini and Claude 3.5 Haiku. Zero errors over 10,000+ probes each. Tight distributions. No time-of-day variation.
Using it as a CI/CD gate
The numbers above show that provider performance is not constant. A model that was fine yesterday might be degraded right now. llmprobe can block deploys when that happens.
# .github/workflows/deploy.yml
- name: Check LLM providers
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
go install github.com/Jwrede/llmprobe@latest
llmprobe probe --fail-on degraded--fail-on degraded exits with code 1 if any endpoint exceeds its TTFT or
latency thresholds. The deploy stops. No degraded model reaches production.
You configure thresholds per model in probes.yml:
providers:
- name: openai
api_key: ${OPENAI_API_KEY}
models:
- name: gpt-4o-mini
thresholds:
max_ttft: 2s
max_latency: 5s
min_tokens_per_sec: 50Based on the 7-day data, reasonable TTFT thresholds would be:
| Model | Suggested max_ttft | Rationale |
|---|---|---|
| GPT-4o-mini | 1.5s | Covers p95 (1,094ms) with margin |
| Claude 3.5 Haiku | 1.5s | Covers p95 (1,106ms) with margin |
| Gemini 2.0 Flash | 3s | Wide tail, needs headroom |
| Llama 3.3 70B | 3s | p95 at 2,221ms |
| DeepSeek Chat | 5s | Naturally slow, tight threshold would flap |
| Mistral Small | 15s | p95 is 10,852ms, only gate on outages |
This turns “I hope the API is fine” into “I know the API is fine, the pipeline checked 30 seconds ago.”
The tool
llmprobe supports OpenAI, Anthropic, Google, Azure, AWS Bedrock, and any OpenAI-compatible endpoint (Groq, Together, Fireworks, DeepSeek, Mistral, OpenRouter, Ollama, vLLM). Each provider is a thin HTTP wrapper with SSE parsing. The Bedrock client implements SigV4 signing and AWS binary event stream parsing from scratch.
go install github.com/Jwrede/llmprobe@latest
llmprobe watch --tui --interval 60sGitHub: github.com/Jwrede/llmprobe
Live benchmark
Since this article was published, I have expanded the experiment into a continuous, automated benchmark. It now tracks 15 frontier models across OpenAI, Anthropic, Google, DeepSeek, and xAI, probed every hour. The model list updates daily based on OpenRouter’s weekly popularity rankings, so new models are picked up automatically.
The live dashboard is at bench.jonathanwrede.de and all raw data is published as JSONL at github.com/Jwrede/llm-bench-data.
Infrastructure code: github.com/Jwrede/llm-bench