Ich habe 6 LLM-APIs 7 Tage lang überwacht. Das habe ich herausgefunden.
60.000 Probes über GPT-4o-mini, Claude 3.5 Haiku, Gemini 2.0 Flash, Llama 3.3 70B, DeepSeek Chat und Mistral Small. Echte Latenzzahlen aus kontinuierlichem Monitoring.
Warum
Wer Anwendungen auf LLM-APIs baut, kennt das Problem: Die Latenzzahlen in der Provider-Dokumentation zeigen den Best Case. Die Nutzer erleben den p95.
Ich habe llmprobe gebaut, ein Open-Source-Go-CLI, das LLM-Endpoints testet und Time to First Token (TTFT), Gesamtlatenz und Generierungsdurchsatz misst. Keine SDKs, nur rohes HTTP und SSE-Parsing.
Ich habe das Tool auf 6 Modelle über OpenRouter gerichtet und eine Woche laufen lassen.
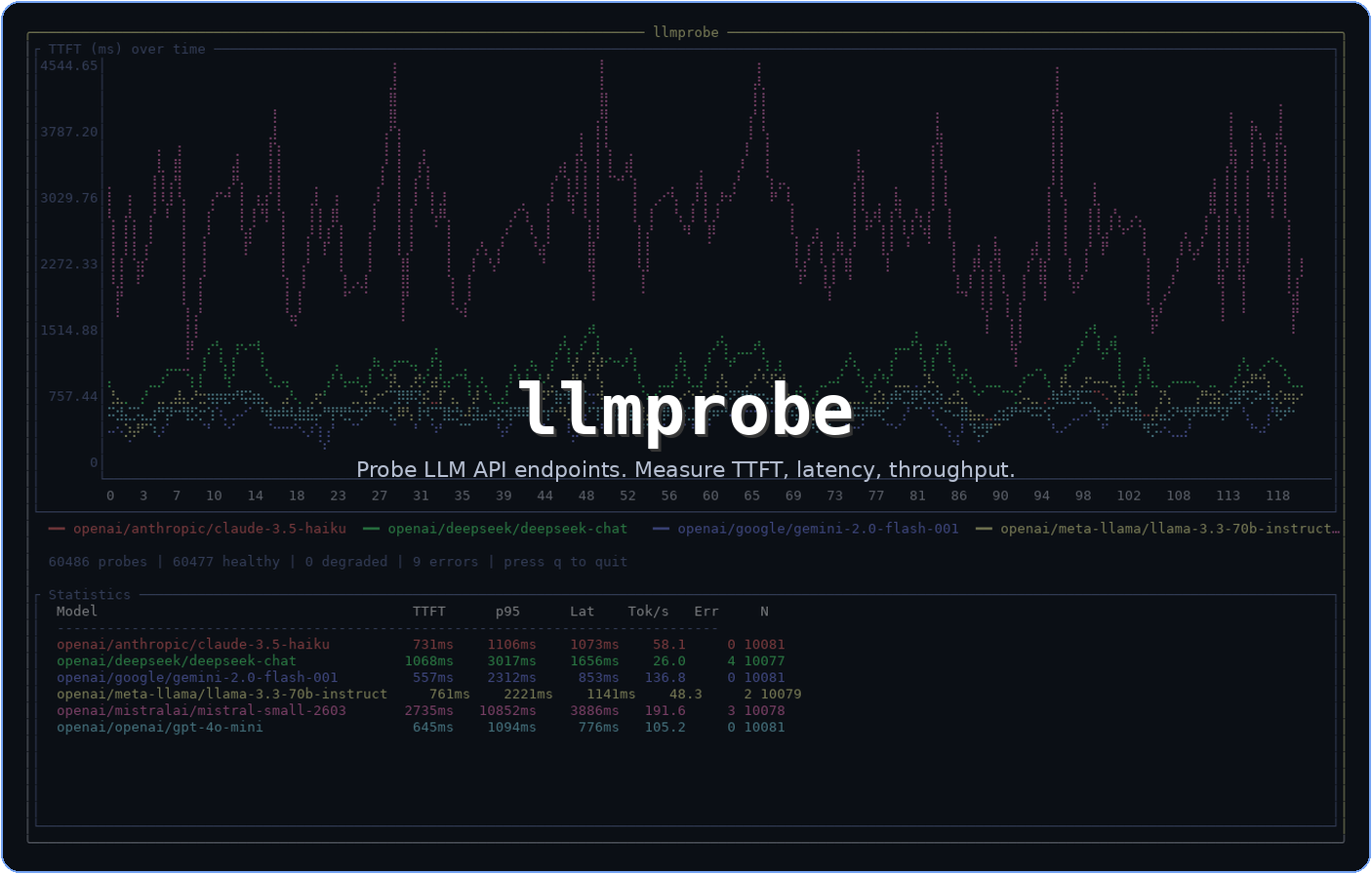
Setup
Alle 60 Sekunden hat llmprobe eine minimale Anfrage (“Hello”, max 20 Tokens) an jedes Modell geschickt. Der Prompt ist bewusst klein gehalten, um Infrastruktur-Latenz von Modell-Rechenzeit zu trennen.
Modelle: GPT-4o-mini, Claude 3.5 Haiku, Gemini 2.0 Flash, Llama 3.3 70B, DeepSeek Chat, Mistral Small.
Gesamtprobes: 60.480 (~10.080 pro Modell).
Die Zahlen
| Modell | TTFT p50 | TTFT p95 | Latenz | Tok/s | Fehler |
|---|---|---|---|---|---|
| GPT-4o-mini | 645ms | 1.094ms | 776ms | 105,3 | 0 |
| Claude 3.5 Haiku | 731ms | 1.106ms | 1.073ms | 58,1 | 0 |
| Gemini 2.0 Flash | 556ms | 2.313ms | 853ms | 136,8 | 0 |
| Llama 3.3 70B | 761ms | 2.221ms | 1.141ms | 48,3 | 2 |
| DeepSeek Chat | 1.068ms | 3.017ms | 1.656ms | 26,0 | 4 |
| Mistral Small | 2.735ms | 10.852ms | 3.886ms | 191,6 | 3 |
p50 vs p95 erzählen unterschiedliche Geschichten
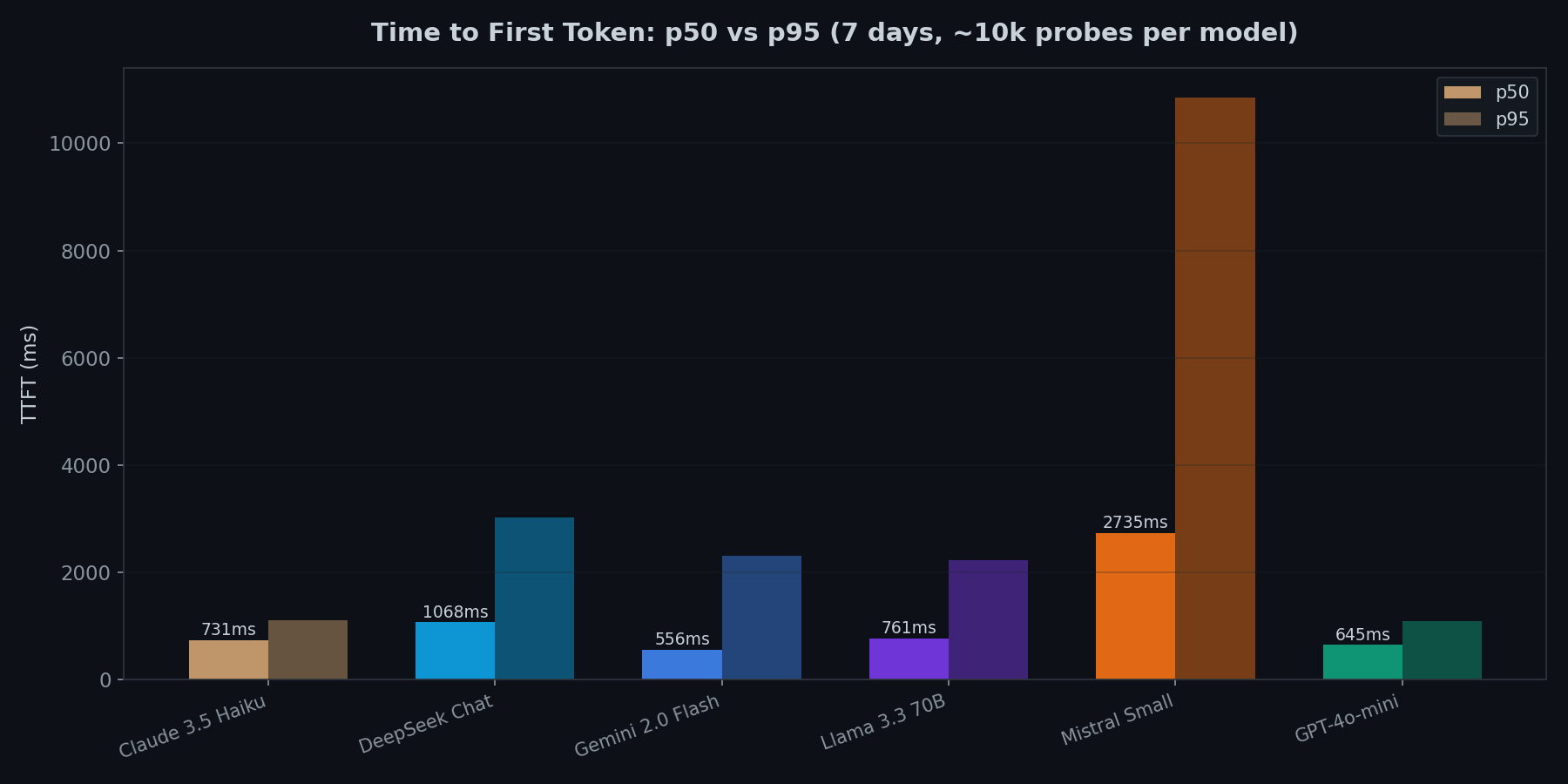
Gemini 2.0 Flash hat den niedrigsten Median-TTFT (556ms), aber der p95 springt auf 2.313ms. Das ist ein 4x-Multiplikator. GPT-4o-mini und Claude 3.5 Haiku sind vorhersagbarer: Ihr p95 liegt nur bei etwa 1,7x des Medians.
Mistral Small ist der Ausreißer. p50 von 2.735ms, p95 von 10.852ms. Etwa 5% der Anfragen brauchen über 10 Sekunden, bis das Streaming beginnt. Das war über die gesamten 7 Tage konsistent, keine temporäre Verschlechterung.
Schnellstes erstes Token != schnellste Generierung
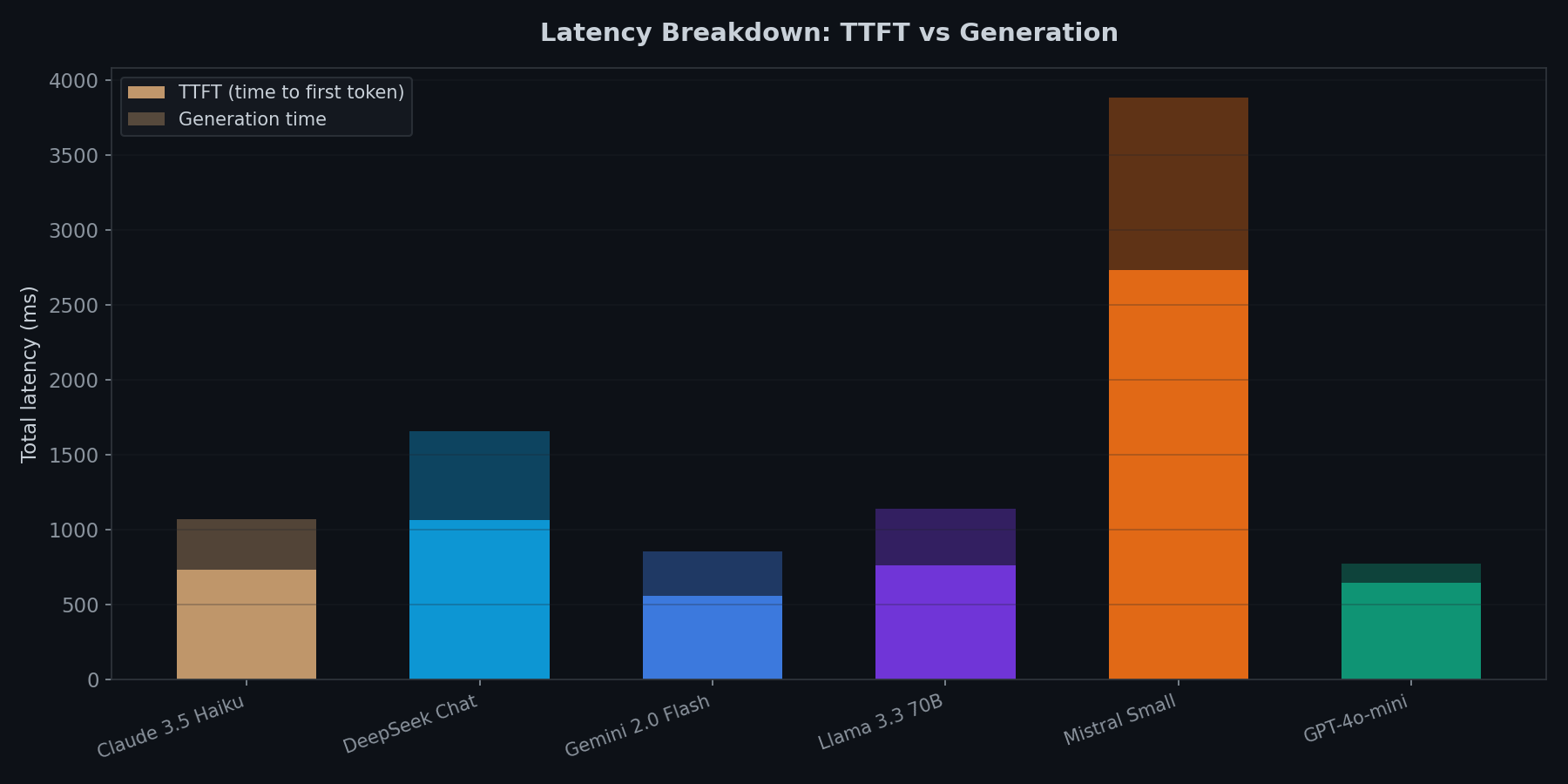
Mistral Small hat den schlechtesten TTFT, aber sobald die Generierung startet, produziert es Token mit 191,6 Tok/s (das schnellste im Test). Gemini 2.0 Flash liegt mit 136,8 Tok/s an zweiter Stelle.
DeepSeek Chat ist in beiden Dimensionen langsam: 1.068ms TTFT und nur 26,0 Tok/s. Die Spanne zwischen schnellstem und langsamstem Durchsatz beträgt fast 8x.
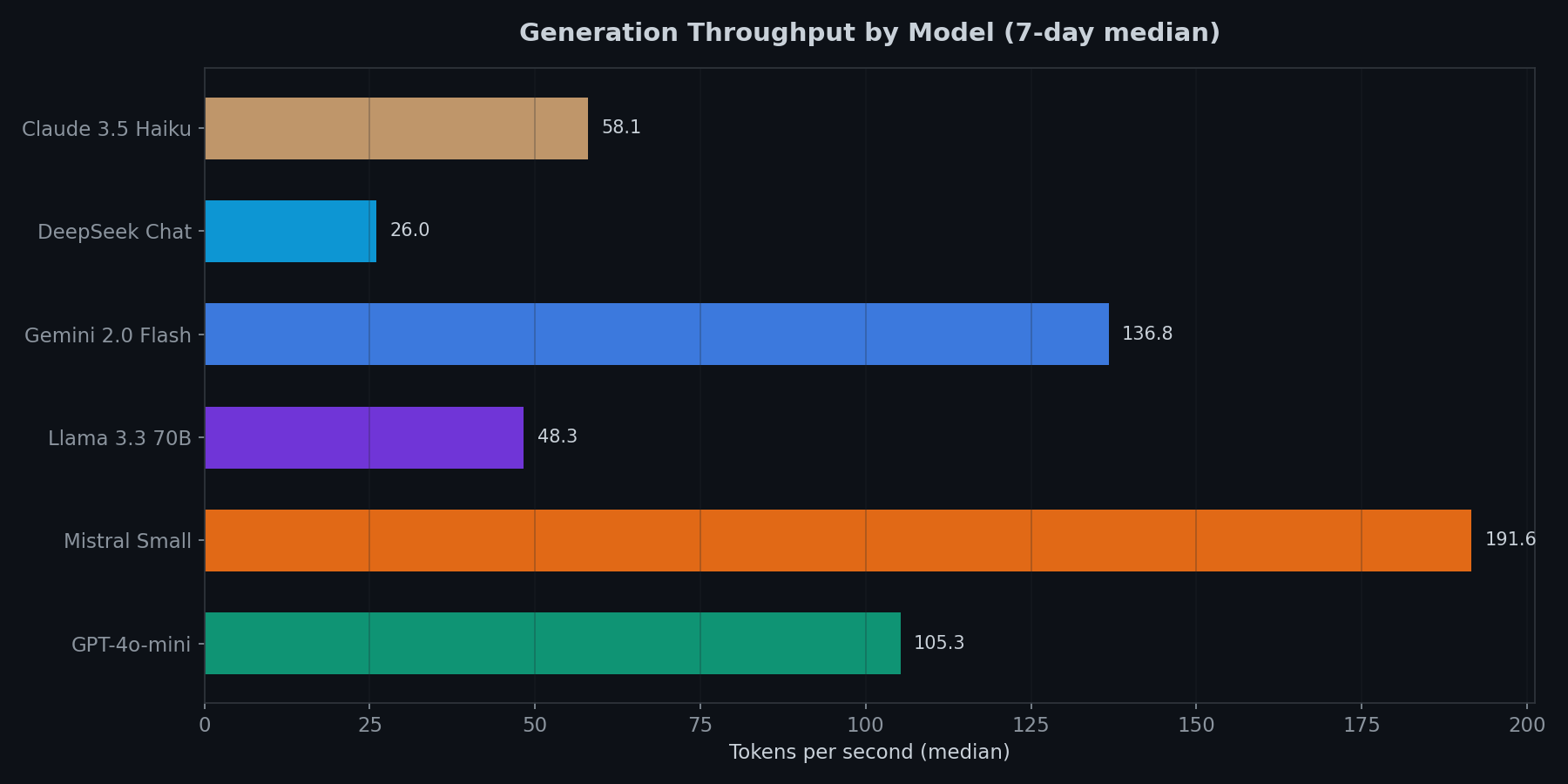
Tail-Latenz ist, wo die Zuverlässigkeit leidet
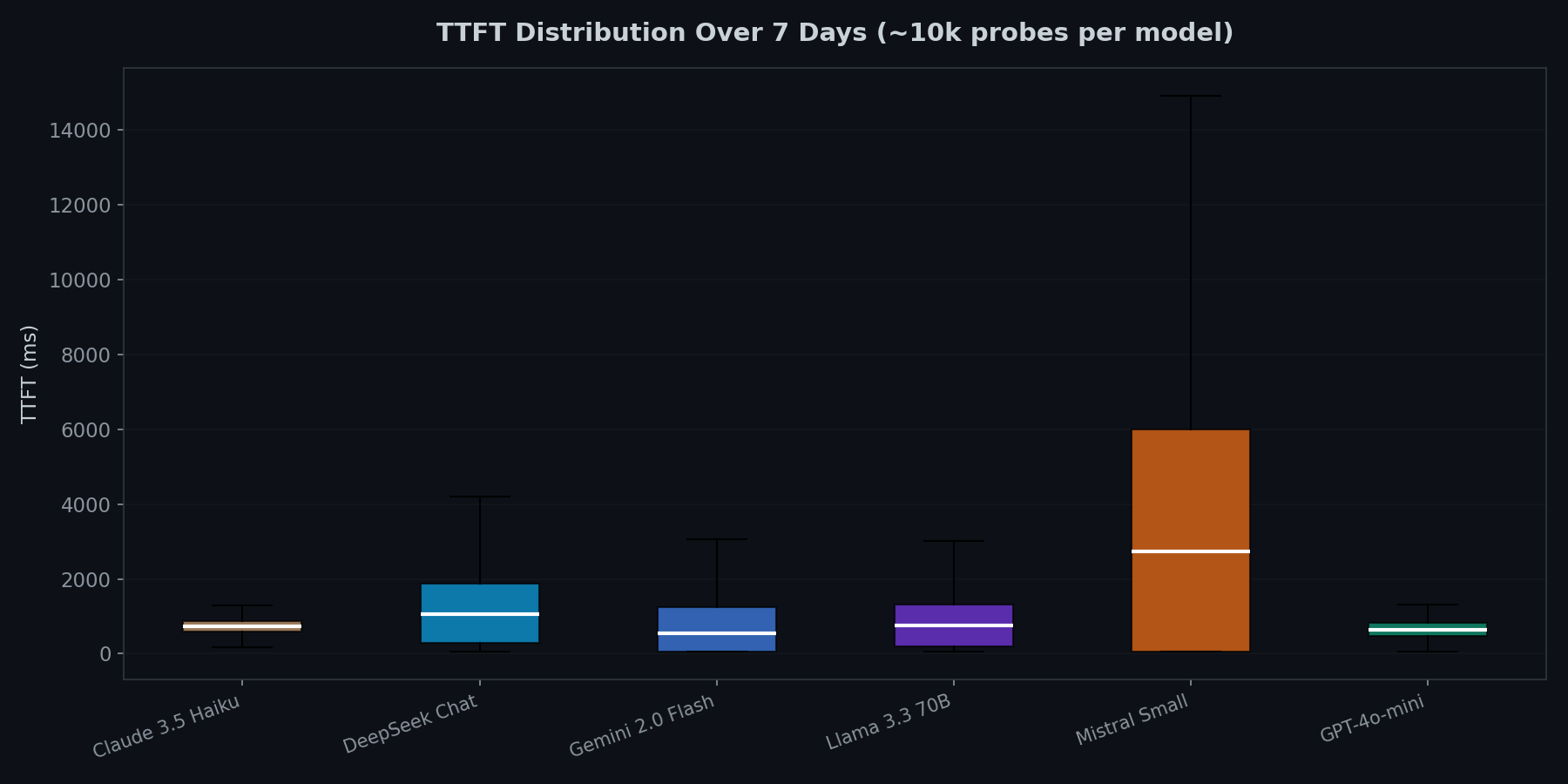
GPT-4o-mini und Claude 3.5 Haiku haben die engsten Verteilungen. Man kann aggressive Timeouts (2s) setzen und trifft sie selten. Gemini und Llama haben längere Tails. Mistrals Verteilung ist so breit, dass es für latenzsensitive Anwendungen praktisch unvorhersagbar ist.
Die 7-Tage-Ansicht zeigt Muster
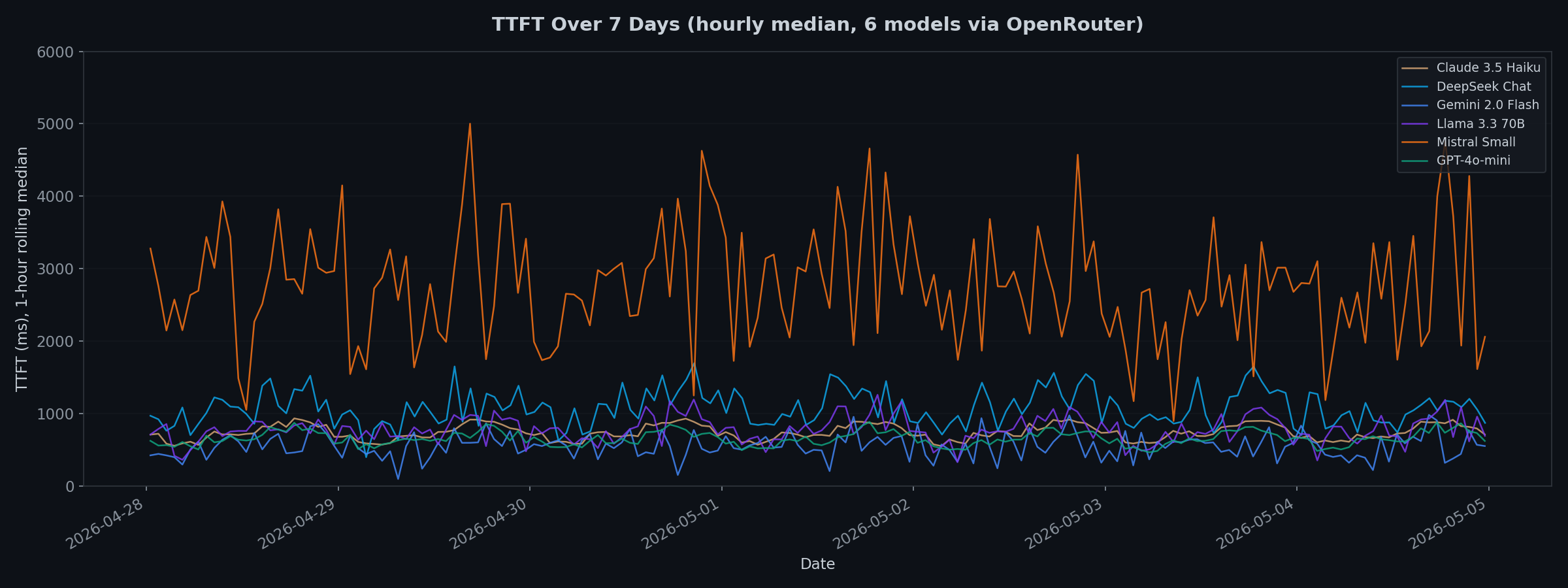
7 Tage Monitoring zeigt, was kurze Benchmarks nicht erfassen:
- Mistral Small hatte periodische Latenz-Spikes über die gesamte Woche, oft über 5.000ms.
- DeepSeek Chat zeigte erhöhte Latenz in bestimmten Zeitfenstern, wahrscheinlich korreliert mit Spitzennutzung in asiatischen Zeitzonen.
- GPT-4o-mini und Claude 3.5 Haiku waren bemerkenswert stabil. Ihre Linien schwanken kaum über die gesamte Woche.
Empfehlungen
Latenzsensitiv (Chatbots, Echtzeit): GPT-4o-mini oder Gemini 2.0 Flash. GPT-4o-mini ist vorhersagbarer; Gemini ist im Median schneller, hat aber breitere Tails.
Durchsatzsensitiv (Batch, Zusammenfassung): Mistral Small, wenn man den TTFT akzeptieren kann. Sonst Gemini 2.0 Flash für den besten Gesamtdurchsatz ohne Latenzstrafe.
Zuverlässigkeit (SLA-gebunden): GPT-4o-mini und Claude 3.5 Haiku. Null Fehler über je 10.000+ Probes. Enge Verteilungen. Keine tageszeitabhängige Variation.
Einsatz als CI/CD-Gate
Die Zahlen oben zeigen, dass Provider-Performance nicht konstant ist. Ein Modell, das gestern gut lief, kann heute degradiert sein. llmprobe kann Deployments blockieren, wenn das passiert.
# .github/workflows/deploy.yml
- name: LLM-Provider prüfen
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
go install github.com/Jwrede/llmprobe@latest
llmprobe probe --fail-on degraded--fail-on degraded beendet mit Exit-Code 1, wenn ein Endpoint seine
TTFT- oder Latenz-Schwellenwerte überschreitet. Das Deployment stoppt.
Kein degradiertes Modell erreicht Production.
Schwellenwerte werden pro Modell in probes.yml konfiguriert:
providers:
- name: openai
api_key: ${OPENAI_API_KEY}
models:
- name: gpt-4o-mini
thresholds:
max_ttft: 2s
max_latency: 5s
min_tokens_per_sec: 50Basierend auf den 7-Tage-Daten wären sinnvolle TTFT-Schwellenwerte:
| Modell | Empfohlener max_ttft | Begründung |
|---|---|---|
| GPT-4o-mini | 1,5s | Deckt p95 (1.094ms) mit Puffer ab |
| Claude 3.5 Haiku | 1,5s | Deckt p95 (1.106ms) mit Puffer ab |
| Gemini 2.0 Flash | 3s | Breiter Tail, braucht Spielraum |
| Llama 3.3 70B | 3s | p95 bei 2.221ms |
| DeepSeek Chat | 5s | Von Natur aus langsam, enger Schwellenwert würde instabil werden |
| Mistral Small | 15s | p95 bei 10.852ms, nur Ausfälle gaten |
So wird aus “Ich hoffe, die API funktioniert” ein “Ich weiß, dass die API funktioniert, die Pipeline hat es vor 30 Sekunden geprüft.”
Das Tool
llmprobe unterstützt OpenAI, Anthropic, Google, Azure, AWS Bedrock und jeden OpenAI-kompatiblen Endpoint (Groq, Together, Fireworks, DeepSeek, Mistral, OpenRouter, Ollama, vLLM). Jeder Provider ist ein dünner HTTP-Wrapper mit SSE-Parsing. Der Bedrock-Client implementiert SigV4-Signing und AWS Binary Event Stream Parsing von Grund auf.
go install github.com/Jwrede/llmprobe@latest
llmprobe watch --tui --interval 60sGitHub: github.com/Jwrede/llmprobe
Live-Benchmark
Seit der Veröffentlichung dieses Artikels habe ich das Experiment zu einem kontinuierlichen, automatisierten Benchmark ausgebaut. Er überwacht jetzt 15 Frontier-Modelle von OpenAI, Anthropic, Google, DeepSeek und xAI, die stündlich geprüft werden. Die Modellliste aktualisiert sich täglich anhand der wöchentlichen Popularitäts-Rankings von OpenRouter, sodass neue Modelle automatisch aufgenommen werden.
Das Live-Dashboard ist unter bench.jonathanwrede.de erreichbar und alle Rohdaten werden als JSONL unter github.com/Jwrede/llm-bench-data veröffentlicht.
Infrastruktur-Code: github.com/Jwrede/llm-bench